
“AI之战”随着声称具有“近乎人类”能力的Claude 3的发布进入高潮
“没有哪个模型在如此广泛的基准测试中击败了GPT-4。”——Willison如是说。

周一,Anthropic[发布了Claude 3](Introducing the next generation of Claude \ Anthropic),这是一系列类似于ChatGPT背后的AI语言模型的三个模型。Anthropic声称这些模型在一系列认知任务中设定了新的行业基准,甚至在某些情况下接近“近乎人类”的能力。现在可以通过[Anthropic的网站获取](Claude \ Anthropic),最强大的模型仅对订阅用户开放。它也通过API为开发者提供。
Claude 3的三个模型代表了递增的复杂性和参数数量:Claude 3 Haiku、Claude 3 Sonnet和Claude 3 Opus。Sonnet现在通过电子邮件注册免费为Claude.ai聊天机器人提供动力。但如上所述,Opus只有在你支付每月20美元的“Claude Pro”订阅服务时,才能通过Anthropic的网页聊天界面获得。所有三个模型都具有200,000个令牌的上下文窗口。(上下文窗口是AI语言模型一次可以处理的令牌数量——单词的片段。)
我们在2023年3月报道了Claude的发布,同年7月发布了Claude 2。每次,Anthropic在能力上略逊于OpenAI的最佳模型,但在上下文窗口长度上超过了它们。有了Claude 3,Anthropic可能终于在性能上赶上了OpenAI发布的模型,尽管专家们还没有达成共识——而且AI基准测试的呈现特别容易选择性地挑选数据。
据报道,Claude 3在各种认知任务上表现出先进的性能,包括推理、专业知识、数学和语言流畅性。(尽管AI研究界对于大型语言模型是否“知道”或“推理”没有共识,但通常使用这些术语。)公司声称,三个模型中最能干的Opus模型在复杂任务上表现出“近乎人类的理解和流畅性”。
这是一个相当大胆的声明,值得更仔细地分析。Opus在某些特定基准测试上可能是“近乎人类”的,但这并不意味着Opus像人类一样具有通用智能(考虑到口袋计算器在数学上是超人的)。因此,这是一个故意引人注目的声明,可以通过附加条件来淡化。
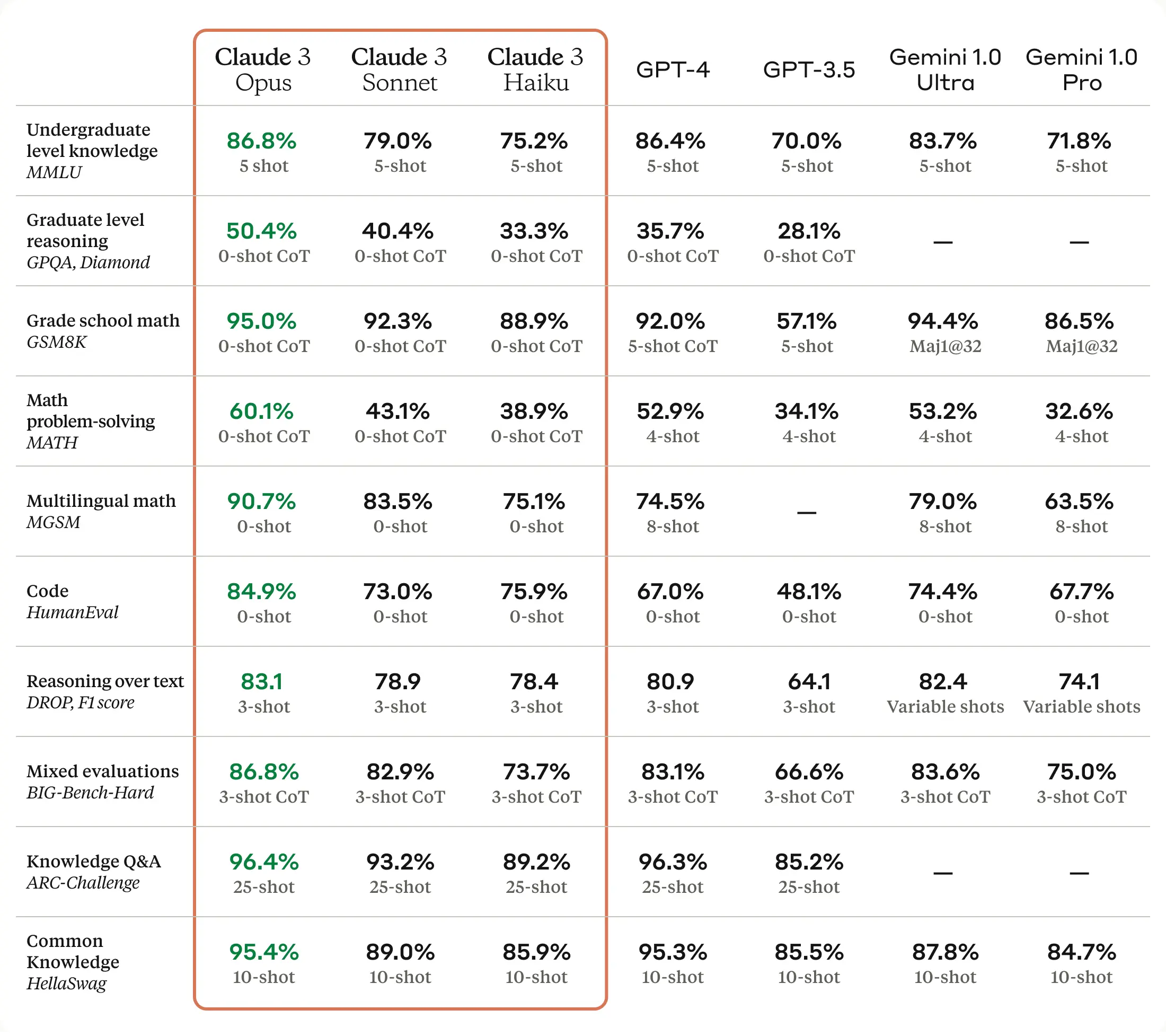
根据Anthropic的说法,Claude 3 Opus在10个AI基准测试中击败了GPT-4,包括MMLU(大学水平知识)、GSM8K(小学数学)、HumanEval(编码)和色彩缤纷的HellaSwag(常识)。其中一些胜利非常微弱,例如在MMLU的五次尝试中,Opus的86.8%对GPT-4的86.4%,而有些差距很大,例如在HumanEval上的90.7%超过了GPT-4的67.0%。但这对于你作为客户来说意味着什么,很难说。
“AI基准测试应该带有一定的怀疑态度,”与Ars讨论Claude 3的AI研究员Simon Willison说。“模型在基准测试上的表现并不能告诉你模型使用起来‘感觉’如何。但这仍然是一个巨大的交易——没有其他模型在如此广泛的广泛使用的基准测试中击败了GPT-4。”
价格和性能的广泛范围
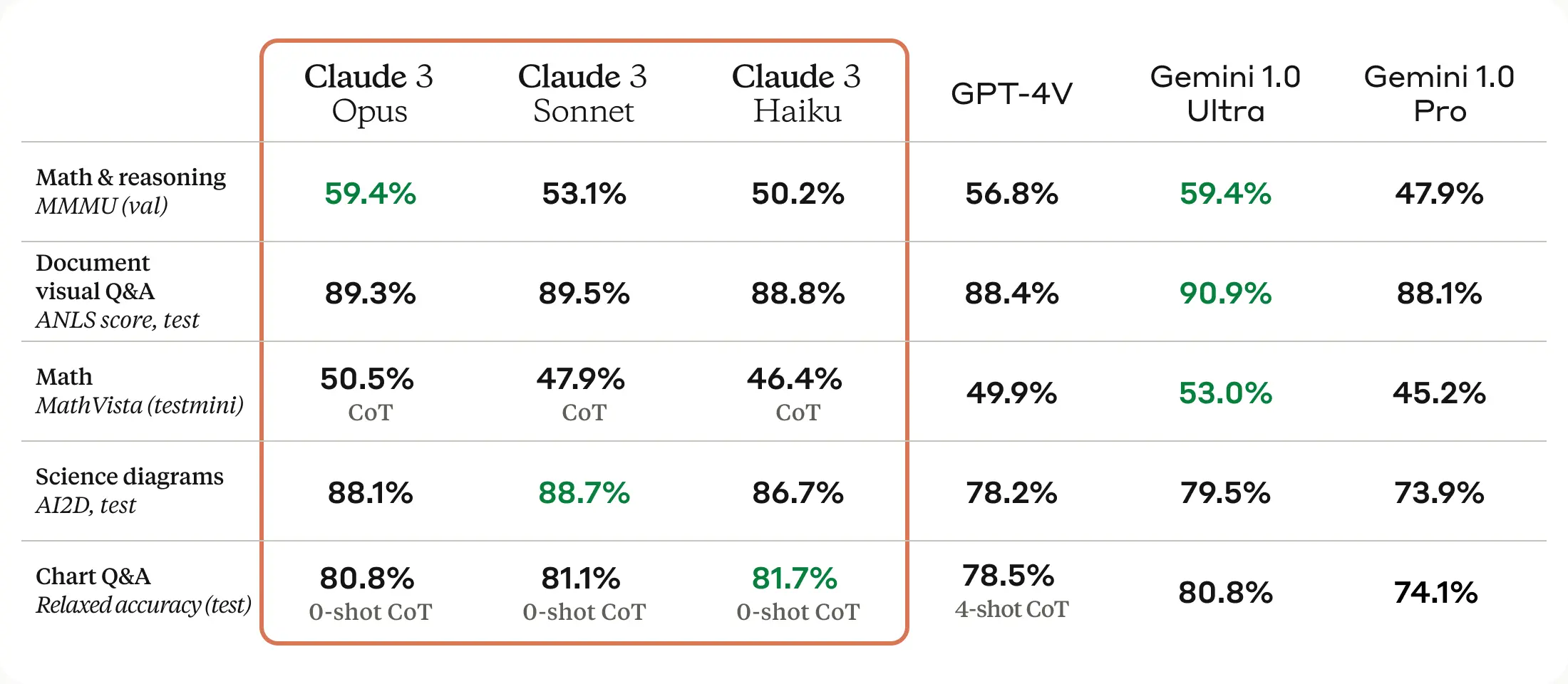
与其前身相比,Claude 3模型在分析、预测、内容创作、代码生成和多语言对话等方面显示出改进。这些模型还据报道具有增强的视觉能力,允许模型处理视觉格式,如照片、图表和图表,类似于GPT-4V(在ChatGPT的订阅版本中)和Google的Gemini。
Anthropic强调,与前一代和竞争模型相比,这三个模型的速度和成本效益有所提高。Opus(最大的模型)是每百万输入令牌15美元,每百万输出令牌75美元,Sonnet(中间模型)是每百万输入令牌3美元,每百万输出令牌15美元,而Haiku(最小、最快的模型)是每百万输入令牌0.25美元,每百万输出令牌1.25美元。相比之下,OpenAI的GPT-4 Turbo通过API是每百万输入令牌10美元,每百万输出令牌30美元。GPT-3.5 Turbo是每百万输入令牌0.50美元,每百万输出令牌1.50美元。
当我们询问Willison关于Claude 3性能的印象时,他说他还没有感受到,但每个模型的API定价立即引起了他的注意。“未发布的最便宜的那个看起来非常有竞争力,”Willison说。“最好的那个非常昂贵。”
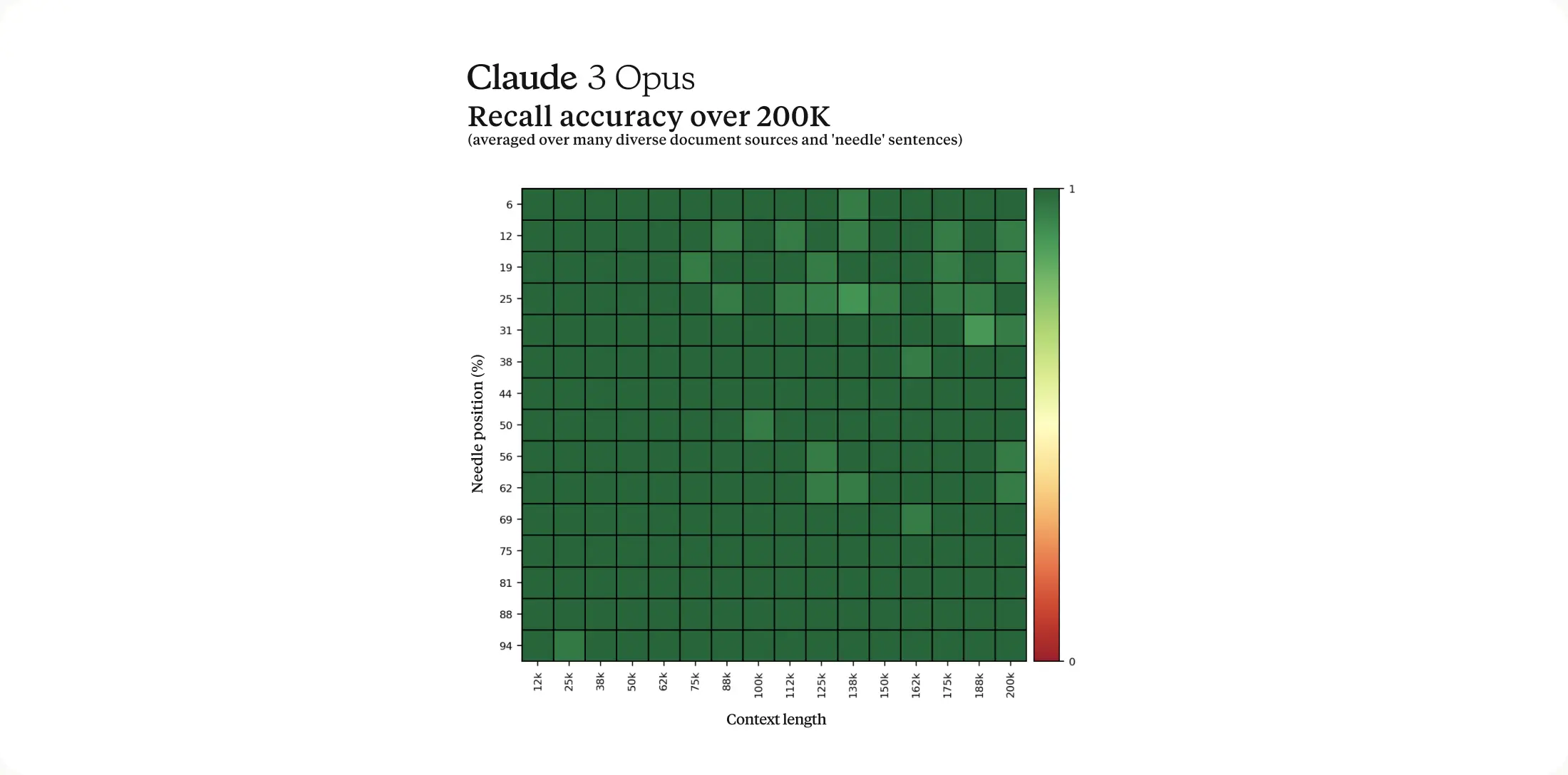
在其他杂项笔记中,据报道,Claude 3模型可以为选定的客户处理高达100万个令牌(类似于Gemini Pro 1.5),Anthropic声称Opus模型在跨越如此巨大的上下文大小的基准测试中实现了近乎完美的回忆,准确率超过99%。此外,公司声称Claude 3模型不太可能拒绝无害的提示,并在减少错误答案的同时展示更高的准确性。
根据与模型一起发布的模型卡,Anthropic部分通过在训练过程中使用合成数据实现了Claude 3的能力增益。合成数据意味着使用另一个AI语言模型内部生成的数据,这种技术可以作为扩大训练数据深度的一种方式,以代表可能在抓取的数据集中缺乏的场景。“合成数据的事情是大事,”Willison说。
Anthropic计划在未来几个月内频繁更新Claude 3模型系列,以及新功能,如工具使用、交互式编码和“高级代理能力”。公司表示,它致力于确保安全措施与AI性能的进步保持同步,并且Claude 3模型“目前几乎没有灾难性风险”。
Opus和Sonnet模型现在可以通过Anthropic的API获得,Haiku将很快跟进。Sonnet还可以通过Amazon Bedrock和在Google Cloud的Vertex AI Model Garden中进行私人预览。
关于LLM基准测试的一点说明
我们注册了Claude Pro,亲自尝试了Opus进行一些非正式测试。Opus在能力上感觉与ChatGPT-4类似。它不能编写原创的爸爸笑话(所有笑话似乎都是从网上抓取的),它在总结信息和以各种风格撰写文本方面做得很好,在逻辑分析文字问题方面表现相当不错,而且确实相对较少出现错误(但当我们询问更晦涩的话题时,我们看到了一些问题)。
所有这些都不是一个决定性的通过或失败,这在计算机产品通常输出硬数字和可量化基准的世界中可能令人沮丧。“又是一例现代AI中的‘氛围’作为关键概念,”正如Willison告诉我们的那样。
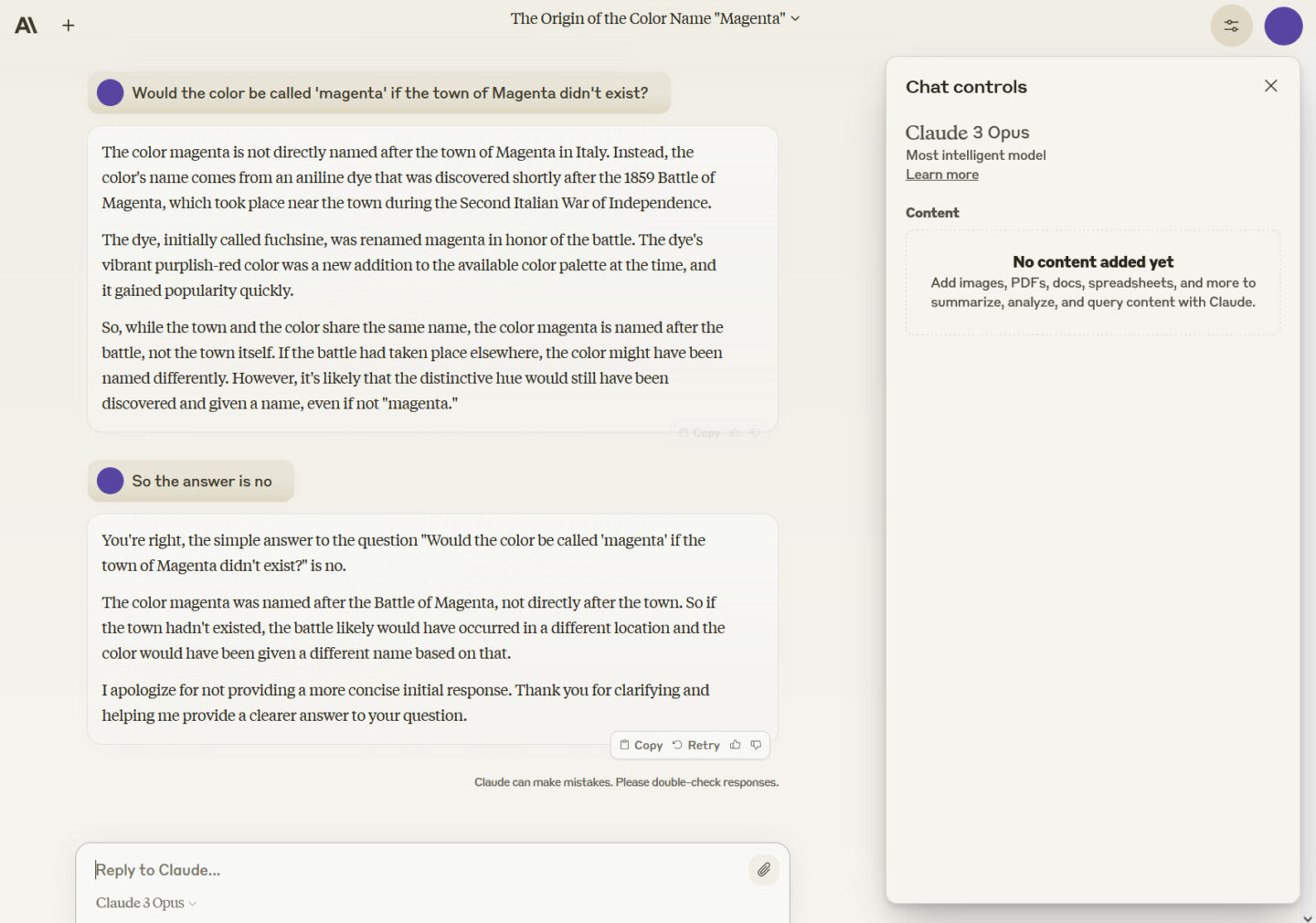
我们询问它:“如果曼贾恩塔镇不存在,这种颜色会被称为“洋红色”吗?”
这是Claude 3 Opus的回答:
这是Claude 2的回答

AI基准测试很棘手,因为任何AI助手的有效性高度依赖于使用的提示和底层AI模型的条件。AI模型可以在“测试”上表现良好(这样说),但未能将这些能力泛化到新的情况。此外,AI助手的有效性高度主观(因此Willison的“氛围”)。这是因为让AI模型成功执行你想要的任务很难量化(例如,在基准度量中),当你给它的任务可能是地球上任何智力领域的任何任务时。有些模型在某些任务上表现良好,而在其他任务上则不然,这可能因人、任务和提示风格而异。
这适用于Google、OpenAI和Meta等供应商的每一个大型语言模型——不仅仅是Claude 3。随着时间的推移,人们发现每个模型都有自己的怪癖,每个模型的优缺点可以通过特定的提示技术来接受或解决。目前看来,主要的AI助手正在形成一套非常相似的能力。
所以,当Anthropic说Claude 3可以胜过目前仍被广泛视为市场领导者的GPT-4 Turbo时,需要带着一点盐粒——或者一剂氛围。如果你在考虑不同的模型,关键是亲自测试每个模型,看看它是否适合你的应用,因为很可能没有其他人能复制你使用它的确切环境。




可以提供GPT账号代充值和升级~

