无论在工作,亦或是学习过程中,经常遇到一些令人烦躁的重复性工作,被领导或导师指派去完成一个自己完全没有了解过的方面的工作,不要着急,不会就问,不好意思问同事导师?那么就来问问GTP吧!
GPT-4.0(Generative Pre-trained Transformer 4.0)是一个先进的大型语言模型,它在学术领域有着广泛的应用潜力。根据搜索结果,GPT-4.0可以为学术研究提供多种支持,包括但不限于以下几个方面:
成果调研 :GPT-4.0可以帮助研究人员快速浏览和理解大量的科技文献,通过其强大的自然语言处理能力,提取关键信息,辅助研究人员进行文献综述和研究背景的梳理。
论文研读 :利用GPT-4.0,研究人员可以更高效地阅读和理解学术论文,模型可以提供对论文内容的摘要、关键点的提取以及可能的研究方向建议。
学术写作 :GPT-4.0可以辅助撰写学术论文,包括生成论文草稿、编辑和润色文本、甚至帮助构建论文结构。它可以根据研究人员提供的指导和上下文信息,生成符合学术规范的文本。
数据分析与可视化 :GPT-4.0可以与数据分析工具结合,帮助研究人员处理和分析数据,甚至生成图表和可视化内容,以支持研究结果的展示。
自动化论文阅读 :通过安装特定的插件,如“ArixGPT”,GPT-4.0可以实现自动化论文阅读,快速从大量文献中提取关键信息。
提高生产力 :GPT-4.0可以帮助研究人员在原型想法设计、识别无用想法、加速数据重新格式化任务等方面提高工作效率,从而节省时间,专注于更有创造性的工作。
多模态技术 :GPT-4.0可以与多模态技术结合,如谷歌的Gemini模型,这可能意味着它能够处理和分析图像、声音等多种类型的数据,为跨学科研究提供支持。
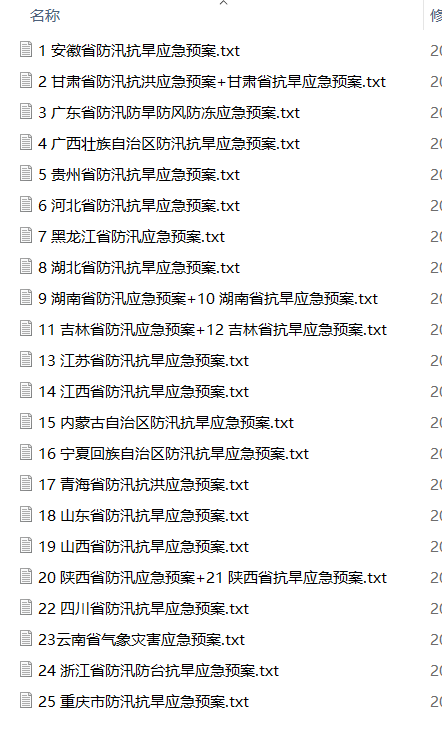
使用示例: 提出要求: 在撰写论文时,需要进行大量的数据分析:例如,对于多个省份的预案文件,需要根据评分标准给出分数(识别关键字,文本包含一个关键词即加一分,无关键词则不得分)
如下,我有二十多个文件需要从中识别关键字,识别到关键字即可加一分,未识别到不得分
当然我们可以用word的搜索功能一篇一篇地找,但关键词有二十多甚至三十个,每一篇搜索将是一个很大的工作量,这时候我们考虑用Python来写一个简单的程序来完成这个任务。但对于没有使用过编程的朋友们,听到编程头就大了?这时候你可以和GPT讲清楚你的要求,就像这样:
于是GPT给出了它的回答,如下: 要使用Python对多个txt文档进行多个关键字检索,并将关键词出现频次统计为Excel表格,你可以按照以下步骤操作:
安装所需的库:
创建一个Python脚本,并使用以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import osimport reimport openpyxlfrom collections import Counterdef search_keywords_in_file (file_path, keywords ): with open (file_path, 'r' , encoding='utf-8' ) as file: content = file.read() keyword_counts = Counter() for keyword in keywords: occurrences = len (re.findall(r'\b{}\b' .format (re.escape(keyword)), content, flags=re.IGNORECASE)) keyword_counts[keyword] += occurrences return keyword_counts def process_files_in_directory (directory, keywords ): keyword_counts = Counter() for filename in os.listdir(directory): if filename.endswith(".txt" ): file_path = os.path.join(directory, filename) keyword_counts += search_keywords_in_file(file_path, keywords) return keyword_counts def save_to_excel (keyword_counts, excel_filename ): workbook = openpyxl.Workbook() sheet = workbook.active sheet['A1' ] = 'Keyword' sheet['B1' ] = 'Frequency' for row, (keyword, frequency) in enumerate (keyword_counts.items(), start=2 ): sheet.cell(row=row, column=1 , value=keyword) sheet.cell(row=row, column=2 , value=frequency) workbook.save(excel_filename) if __name__ == "__main__" : keywords_to_search = ['keyword1' , 'keyword2' , 'keyword3' ] folder_path = 'path/to/txt/files' excel_file = 'output.xlsx' keyword_counts = process_files_in_directory(folder_path, keywords_to_search) save_to_excel(keyword_counts, excel_file)
请替换'keyword1', 'keyword2', 'keyword3'为你想要搜索的关键字,'path/to/txt/files'为包含txt文件的文件夹路径,'output.xlsx'为Excel文件的输出路径。运行脚本后,将生成一个包含关键词频次统计的Excel文件。
修改(详细)要求: 这个时候我意识到我只需要知道关键词是否出现,而不需要统计其词频,那么我就对它说:
于是得到它的回答:
理解了你的需求,下面是修改后的程序,将关键词在文本中的出现与否标记为1或0,最后将结果保存到Excel文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import osimport openpyxldef search_keywords_in_file (file_path, keywords ): with open (file_path, 'r' , encoding='utf-8' ) as file: content = file.read() keyword_occurrences = {keyword: int (keyword.lower() in content.lower()) for keyword in keywords} return keyword_occurrences def process_files_in_directory (directory, keywords ): keyword_occurrences_list = [] for filename in os.listdir(directory): if filename.endswith(".txt" ): file_path = os.path.join(directory, filename) keyword_occurrences = search_keywords_in_file(file_path, keywords) keyword_occurrences_list.append({"Filename" : filename, **keyword_occurrences}) return keyword_occurrences_list def save_to_excel (keyword_occurrences_list, excel_filename ): workbook = openpyxl.Workbook() sheet = workbook.active sheet['A1' ] = 'Filename' for col, keyword in enumerate (keywords, start=2 ): sheet.cell(row=1 , column=col, value=keyword) for row, data in enumerate (keyword_occurrences_list, start=2 ): sheet.cell(row=row, column=1 , value=data["Filename" ]) for col, keyword in enumerate (keywords, start=2 ): sheet.cell(row=row, column=col, value=data[keyword]) workbook.save(excel_filename) if __name__ == "__main__" : keywords_to_search = ['keyword1' , 'keyword2' , 'keyword3' ] folder_path = 'path/to/txt/files' excel_file = 'output.xlsx' keyword_occurrences_list = process_files_in_directory(folder_path, keywords_to_search) save_to_excel(keyword_occurrences_list, excel_file)
请将'keyword1', 'keyword2', 'keyword3'替换为你想要搜索的关键字,'path/to/txt/files'为包含txt文件的文件夹路径,'output.xlsx'为Excel文件的输出路径。运行脚本后,将生成一个包含关键词出现情况的Excel文件。
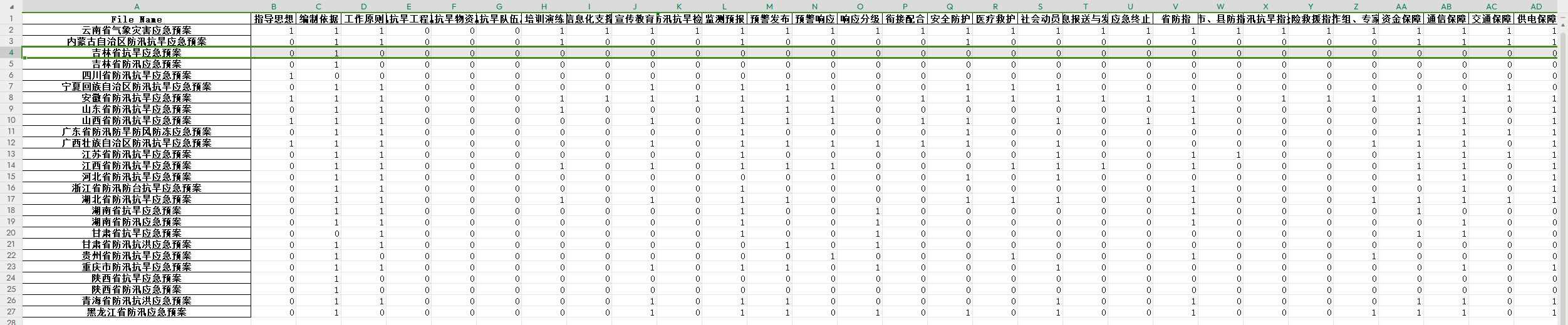
最后,按照它给出的提示,修改你的文件路径,保存为py文件(Python格式的文件)然后在win处右键打开终端,输入”python {你的py文件名}.py”
结果 我就得到了我想要的数据统计:
今天的分享就到这里,希望对大家有帮助